本稿はTeX & LaTeX Advent Calendar 2023の16日目の記事です。15日目はh-kitagawaさんでした。17日目はYarakashi_Kikohshiさんです。
こんにちは、ワトソンです。気付けばほぼ1年ぶりのブログ更新になってしまいました。特にTwitter(現自称X)ユーザの皆さん、お元気でしょうか。私はかのプラットフォームの度重なる意味不明な仕様変更に嫌気が差して、ほとんど使うのをやめてしまいましたが、Blueskyではつつがなく過ごしております。
Twitterといえば、Twitter APIが約半年前の変更により無料での利用は事実上不可能になってしまいました。有料プランの利用は、私のような趣味目的ではちょっと非現実的な予算になってしまうため、私が運用していたいくつかのプログラムやボットについてもこれを機に引導を渡すこととなりました。
@latex_botも、こうして終焉を迎えたボットの1つです。このボットアカウントは、その稼働を開始した初日に一度だけツイートをしたのですが、それは2018年4月9日のことでした。
Happy LaTeXing!
— LaTeX. Not LaTex. (@latex_bot) April 9, 2018
そして、Twitter APIの仕様変更により、このボットが最後の「いいね」をしたのが2023年6月14日。この日、@latex_botは5年2ヶ月と5日(1,893日)の短い生涯を終えました。
この間、@latex_botはLaTeXをLaTex等とさまざまにスペルミスするツイートを見かける度に、「いいね」を送ってきました。5年間で送ったいいねはおよそ3万を数えます(2023年12月10日時点でカウント。削除された投稿は除く)。上で触れた最初のツイート以外には、一切つぶやくことはありませんでしたが、ありがたいことに944人(同じく2023年12月10日時点)もの方がフォローをしてくださったようです。
本稿では、このボットの誕生に至る経緯とその実績(いいねしたツイート)の簡単な分析を通して、その生涯を振り返りたいと思います。
開発の経緯
@latex_bot開発のきっかけはこのツイートです。
LaTexにいいねする"LaTeX. Not LaTex"ボットを運用してみてはどうか
— 専門性・売上・原稿 (@golden_lucky) April 9, 2018
経緯はこれでほぼ終わりですが、いちおうもう少し詳しく書いてみます。
もとはといえばTeXの生みの親であるKnuthがThe TeXbookの第1章の1ページ目でTeXの発音と綴りにやたらとこだわったために、TeXの表記はTとXを大文字、eは小文字と正しく表記することがTeXのコミュニティでは絶対のお約束として広がることとなりました。これはLaTeXについても同様で、LとTとXは大文字、aとeは小文字で正しく表記することが、ある種のお約束として大切にされてきました。
Knuthがそういった凝り性な人物であったためかはわかりませんが、TeX界隈の一部にはどんなに細かいことでもしっかりと指摘するような文化的土壌がありました。ここ数年はだいぶ穏やかな雰囲気になってきたような気もしますが、@latex_botが作られた頃は「#TeXヤクザ」や「#TeX警察」といったハッシュタグもよく用いたように記憶しています。
こういう文化も内輪で面白がっているうちはよいのですが、大文字・小文字のわずかな違いを「間違い」とされるような、こういった細かい指摘というのはTeXやLaTeXに詳しくない方からすれば鬱陶しく思われかねないところでもあります。特に、TwitterのようなSNSはその通知のしくみ上、普段接点のないアカウントからメンションや引用があると、それだけでちょっとした衝撃を相手に与えかねません。その上その通知の中身が、何気ないツイートの中の、lやxが大文字か小文字かなどということに関する誤りの指摘であると、場合によっては苛立ちを感じてしまうこともあるわけです。
私もTeX/LaTeXの愛好家の1人なので、できればLaTeXもなるべく正しい表記が使われる世界線であって欲しいのですが、それを見かける度に人が指摘するというのは野暮のようです。そこで、LaTeXの誤表記について少しコミカルで笑って流せる形で、かつ正しい表記方法を周知できるような、そんなしくみが作れないかと考えられたのが@latex_botです。
先ほど紹介したツイートにも出てきていますが、このボットには@ocamlbotという類似の先例があります。これは関数型プログラミング言語OCamlについて、そのスペルミスを検出しては「いいね」を送るボットです。このボット仕様の巧みなところはアカウント名でスペルミスを指摘している一方、取っている行動は「いいね」であるところです。これがリプライだとやはり鬱陶しさがありますし、RTではむしろ公開処刑のようでさらに人を激昂させそうです。いいねでもアカウント名をみて皮肉的だと怒る人もいなくはないのですが、理由は何であれ「他人からもらえば嬉しいもの」と好意的に受け止められやすいのがいいねなので、うまくできているというわけです1。
実装
諸般の事情で@latex_botの実装については公開してきませんでした。現在は運用を終了している上に、もはや現在のTwitter APIでは稼働もできないということで、大したコードでもないですが公開します。
アカウント名は“LaTeX. Not Latex.”ですが、実際はLaTex以外の多くのスペルミスも検出しています。これについて「どういう実装なんだろう?」と検討しているツイートもいくつか見かけたことがありますが、実は全パターンのベタ打ちです。特に深い理由はないのですが、毎回全バリエーションを生成するのは計算資源が無駄だからということにしておきます。
誤爆(LaTeXの話をしていないツイートをいいねしてしまうこと)を防ぐために、色々とアドホックな処理をしており実装がちょっとごちゃごちゃしています。まず、“latex”, “LATEX”, “Latex” は検出対象としていません。latexやLATEXは文脈によっては正しい表記になり得ます(たとえばLaTeXのコマンド名は正しくlatexです)し、Latexについても英語では文頭に現れる場合には正当な単語であることがあります。これらを対象に含めると、あまりにも誤爆が多くなってしまうので避けました。
それ以外には、ゴムやラバーの意味で“latex”を用いているツイートを避ける必要がありました2。これについては厳密に行うのは困難です。機械学習を用いた近年の自然言語処理技術ではある程度の精度で分類できるとは思いますが、計算リソースが必要ですし、このボットについてそこまで厳密に分類するモチベーションが特になかったので、アドホックな処理で済ませています。実は、Twitterの検索クエリにfilter:safeを設定し、いくつかの禁止ワードを含むものを除外するだけで、それなりの精度でLaTeXに関連するツイートを選別することができます。基本的にはrecallよりもprecisionを重視する(つまり、取りこぼしはあってもよいが、誤検知はなるべく避ける)方針でこのヒューリスティクスを採用していました。
誤表記が検出されたツイートの分析
ここからは、@latex_botがその生涯をかけて送ってきたいいねの対象がどのようなものであったのか、簡単にみていきたいと思います。
Twitterでは自分のアカウントに紐付くデータをダウンロードすることができます(Twitter公式のヘルプ)。この中にはいいねの全履歴も含まれています。data/like.jsというファイルがそのデータです。中身はJavaScriptですが、辞書のアサイメントが1つあるだけなので、ほんの少し編集すればJSONファイルとして扱うことが可能です。
2023年12月10日時点のダンプデータを分析すると、@latex_botの全いいね履歴は28,382件でした。この日までに削除された投稿は含まれていないと思われるので、実際のいいねの数はこれよりはいくらか多かったのでしょう3。
いいねの履歴に含まれているデータはあまり多くはなく、次の3種類です。
expandedUrl: ツイートのURLfullText: ツイートの中身(テキスト)tweetId: ツイートID
実質テキストのみということです。ツイートURLにアクセスすればもう少し多くの情報を取ることができると思いますが、あまり高頻度でリクエストするとよくなさそうなので、今回はやめておきました。
月別いいね数
Twitterからダウンロードしたデータには日時の情報が含まれていませんが、サーバ上に残った全件ログから@latex_botがその稼働期間中、どのぐらいのいいねを送っていたのかを月ごとに集計してみました。
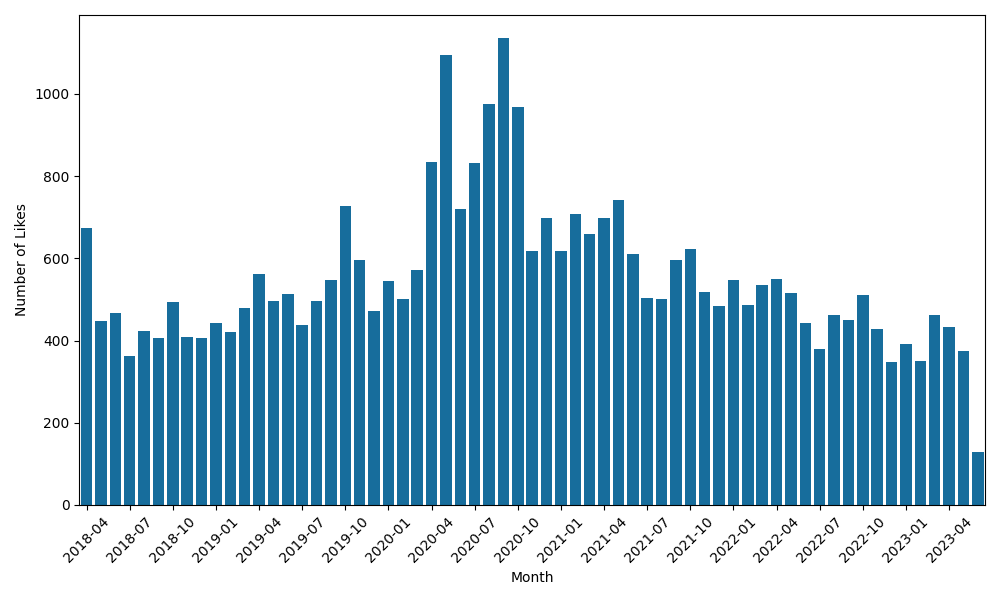
2020年の上半期に一時的にいいねの数が増えていそうですが、他の期間はほぼ一定のようです。残念ながら@latex_botの存在によってミススペルをする人が減少する傾向にあった、ということは特になかったようですね……
言語の分布
まず、LaTeXの誤表記が検出されたツイートは、どの言語で書かれていたのでしょうか。言語の特定にはlangdetectというPythonライブラリを利用しました。URLだけのツイートなど、言語の特定が不可能なものは集計から除外しています。頻度が上位10位以内の言語(それ以外は右端に合計値をバーにしています)の分布を以下に示します。
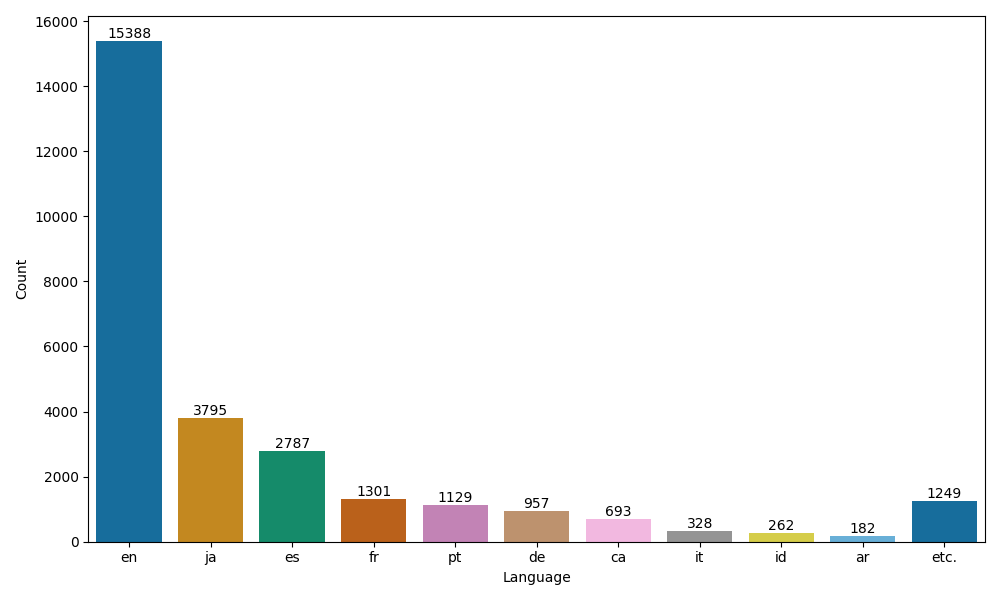
予想に違わず、英語が圧倒的です。日本語は2番目でした。これについては、Twitterが日本で特に人気という事情も関係していそうです。
ただし、3位以降の顔ぶれがTwitterのユーザ数だけでは説明がつかなそうです。ユーザ数の順位では、アメリカ、日本に続く3位以降はインド(ヒンディー語など)、ブラジル(ポルトガル語など)、インドネシア(インドネシア語など)のようですが、LaTeXの誤表記が多く見られたのはスペイン語、フランス語、ポルトガル語の順でした。このあたりの違いを見るに、それぞれの言語話者のLaTeXユーザ数も関係していると考えられます。
リプライ(返信)
検出されたツイートのうちTwitter上のリプライにあたるもの、すなわち@からはじまるアカウント名が冒頭にあるものは10,538件(37.1%)でした。このうち@latex_bot宛のものは16件です。ユーザ間の会話の中で現れる誤表記もかなり多かったようです。
誤表記の種類
実装コードに列挙されているように、@latex_botは28種類のLaTeX誤表記を検出してきました。これらの誤表記の登場頻度はどのような分布になっているのでしょうか。また上位10件を示してみます。
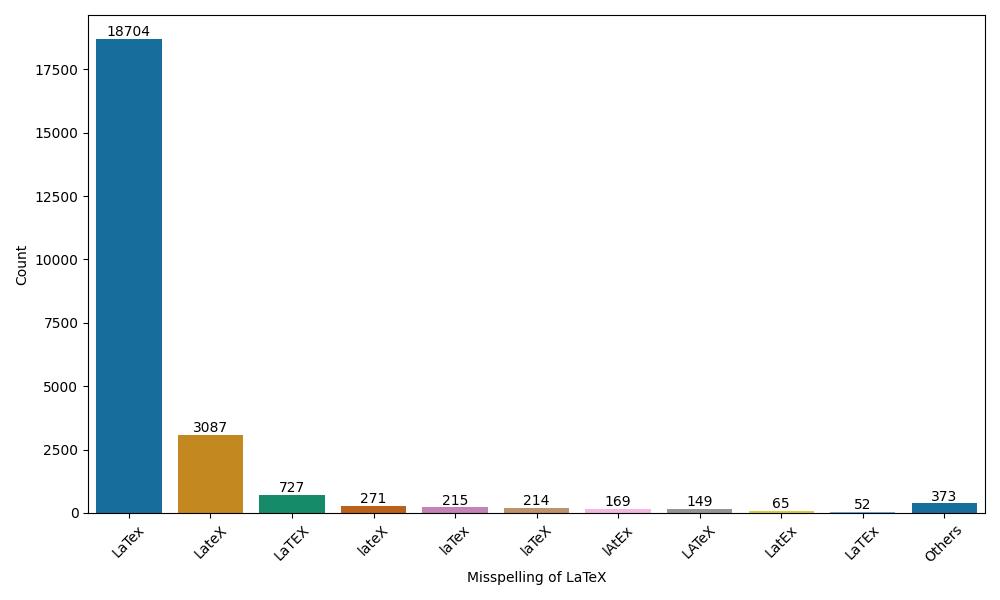
やはりLaTexが圧倒的大多数でした。ボットの名前は“LaTeX. Not LaTex.”で最も妥当だったということですね。2番目のLateXも結構頻出だったようです。そこからは低頻度になりますが、LaTEX、lateX、laTexと続きます。
1つのツイートに上記のうちの複数パターンの誤りが含まれている例も77件ありました。具体的な中身を見てみると、当ボットがLaTex以外も検知するのでその挙動を試すようなものや、LaTeXの誤表記そのものを話題にしているもの(いままさにこのセクションで話しているように、「こういう誤表記が多い/許せる」など)が中心のようです。それ以外では、@latex_botのオマージュと思われる診断メーカーの診断結果ツイートも結構捕捉されていました……
おわりに
TwitterのAPI改悪にともない、数多くのボットが運用終了を余儀なくされました。@latex_botもその1つです。Twitterの歴史はサードパーティ開発者が形作ってきた部分も多々あると思われるので、このような終わり方は残念ですが、一時代の終わりということで仕方がありません。
Twitterとそのプラットフォーム上のボットが全盛の時代の中で、@latex_botは独自の役割を果たしてきました。このボットのいいね行動に対するTwitterユーザの反応はときどき検索等で確認していましたが、概ね好意的に評価していただいたようでした。あまりに悪く言われているようであれば運用をやめようと思っていたのですが、「そうか知らなかった! 今後は気をつけるよ」「なるほど面白いね」というような反応が多かったのは、開発者としては密かに喜ばしいことでした。
皆さんに面白がってもらいつつ、LaTeXの正しい表記を少しでも広げることにつながっていたのであれば、このボットは十二分にその役割を果たすことができたと言えるでしょう。正しく表記してもらえることが増えたLaTeXも、きっと幸せなことでしょう。
以上、LaTeXが幸せになる話でした。
主な更新履歴
- 2023-12-17: サーバのログデータ解析結果を追記
- 2025-12-13: スタイルの更新