前回はTeX by Topic第1章に関連してTeX処理系の挙動を理解するための4プロセッサモデルを導入しました。今回は第2, 3章に対応してカテゴリーコードについて少し細かな事項を扱っていこうと思います。各カテゴリーコードの詳細を述べるにあたり、一部には第10章の内容なども含まれています。
なお、本稿のほとんどの部分では文字セットとしてASCII文字だけを考えることにします。pTeX系列の処理系における和文文字の扱いなどは本稿最後の節で考察します。
カテゴリーコードのキホン
カテゴリーコードはTeXにおける個々の文字の“役割”を規定する重要な値です。一般的なTeXの処理系には次の表に示す16種類のカテゴリーがあります。
| カテゴリーコード | 役割(種類) | 通常この役割を担う文字 |
|---|---|---|
| 0 | 制御綴を開始 | \ |
| 1 | グループの開始 | { |
| 2 | グループの終了 | } |
| 3 | 数式・非数式の切り替え | $ |
| 4 | アライメントの区切り | & |
| 5 | 行の終了 | ^^M(文字コード13) |
| 6 | パラメタ文字 | # |
| 7 | 上付き文字 | ^ |
| 8 | 下付き文字 | _ |
| 9 | 無視される | ^^@(文字コード0) |
| 10 | 空白文字 | ␣(文字コード32) |
| 11 | 英文字 | A-Z,a-z |
| 12 | 記号 | 0-9,!,?ほか多数 |
| 13 | アクティブ文字 | ~ |
| 14 | コメントの開始 | % |
| 15 | 無効文字 | ^^?(文字コード127) |
\catcodeプリミティブを用いると、TeX言語からカテゴリーコードにアクセスすることができます。すなわち\catcode<number>全体を1つのカウンタレジスタのように操作することができ1、これを介してカテゴリーコードの取得や変更(代入)を行います。
ここで<number>はカテゴリーコードにアクセスしたい文字の文字コードに対応する数値表現です2。<number>の書き方はいくつかありますが、\catcodeと共に使う場合には`<char>または`\<char>を用いて指定すると便利なことが多いでしょう。例えば、通常カテゴリーコードが12の文字@のカテゴリーコードを11に変更するには次のようにします。
\the\catcode`@ %=>12
\catcode`@=11
\the\catcode`@ %=>11
ただし\catcode<number>に0から15の範囲にない数値を代入しようとするとエラーになります。
TeXにおける初期設定
前掲の表では「通常この役割を担う文字」というカラムにplain TeXやLaTeXにおける設定を記載しましたが、これはTeXそのものが元来的に設定している分類ではありません。何のフォーマットも読み込んでいない素のTeX(iniTeX)におけるカテゴリーコードの“初期設定”は以下の通りです:
- バックスラッシュ
\はカテゴリーコード0 - 改行文字(文字コード13)はカテゴリーコード5
- ヌル文字(文字コード0)はカテゴリーコード9
- 空白文字(文字コード32)はカテゴリーコード10
- 英文字(a-zおよびA-Z)はカテゴリーコード11
- パーセント
%はカテゴリーコード14 - 無効文字(文字コード127)はカテゴリーコード15
- 上記以外の文字はすべてカテゴリーコード12
ご覧の通り、iniTeXおいては12以外のカテゴリーコードが割り当てられている文字はほんのわずかで、多くの文字にはカテゴリーコード12が割り当てられています。カテゴリーコードの変更を行わない限りグループを作ることすらできません。
そのためフォーマットファイルの冒頭ではまずカテゴリーコードに関する記述が行われます。例えばplain.texの冒頭部分は以下のようになっています。
\catcode`\{=1 % left brace is begin-group character
\catcode`\}=2 % right brace is end-group character
\catcode`\$=3 % dollar sign is math shift
\catcode`\&=4 % ampersand is alignment tab
\catcode`\#=6 % hash mark is macro parameter character
\catcode`\^=7 \catcode`\^^K=7 % circumflex and uparrow are for superscripts
\catcode`\_=8 \catcode`\^^A=8 % underline and downarrow are for subscripts
\catcode`\^^I=10 % ascii tab is a blank space
\chardef\active=13 \catcode`\~=\active % tilde is active
\catcode`\^^L=\active \outer\def^^L{\par} % ascii form-feed is "\outer\par"
latex.ltxの場合はもう少し複雑ですが、基本的には同じように冒頭部分でほとんどのカテゴリーコードの設定を行います。また、LaTeXはこれらのカテゴリーコード設定を行う前に{のカテゴリーコードが1でないかどうかを調べることによって「LaTeXが最初に読み込まれたフォーマットである」ことを確かめています。
\ifnum\catcode`\{=1
\errmessage
{LaTeX must be made using an initex with no format preloaded}
\fi
カテゴリーコードと4プロセッサモデル
ここでは少し、前回の記事で導入した4プロセッサモデルとカテゴリーコードの関係について考えてみましょう。
質問1:カテゴリーコードが影響を与えるのは入力プロセッサだけか?
答えは「いいえ」です。確かにカテゴリーコードはTeXの字句解析(トークン化)に大きな影響を与えますが、その効果範囲は字句解析のみに留まりません。実は文字トークンというのは単なる“文字コード”ではなく“〈文字コード、カテゴリーコード〉の組”です3。したがって、トークンリストを渡される入力プロセッサ以降のプロセッサは、文字コードだけでなくカテゴリーコードの情報も受け取ることができ、もちろんその値次第で異なる振る舞いをすることになります。
質問2:カテゴリーコードを確定するのは入力プロセッサか?
今度の答えは「はい」です。文字トークンに含まれるカテゴリーコードの情報は、原則として展開プロセッサ以降の処理によって変更することはできません4。
入力プロセッサのオートマトンモデル
TeXの入力プロセッサの挙動(字句解析)は下に示す決定性有限オートマトンを考えることで理解することができます。すなわち入力プロセッサは$N$, $M$, $S$の3つの内部状態をもち、読み込んだ文字のカテゴリーコード次第で次の状態に遷移していく機械とみなすことができます。
このオートマトンモデルは、TeXのコメントやサーカムフレックス・メソッド(後述)については考慮されていないため飽くまで模擬的なものですが、それでもTeX言語における連続した空白文字の扱われ方やTeXコードの中でインデント可能である理由など、TeXの字句解析の大まかな挙動を理解するのに役立ちます。
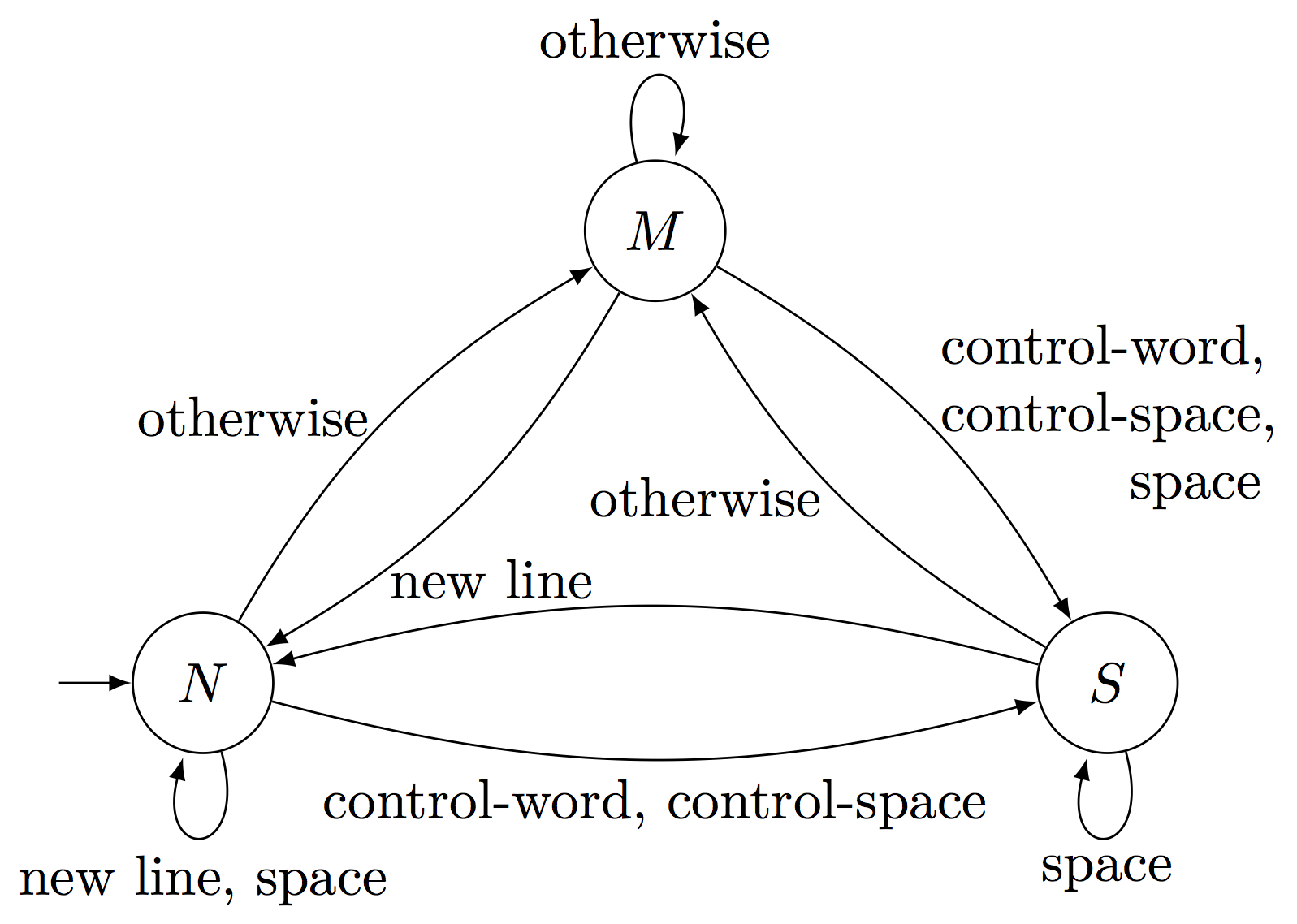
状態$N$:new line
入力プロセッサは新しい行が開始するときには常に状態$N$にあり、それが状態$N$に遷移してくる唯一のシチュエーションです。入力プロセッサが状態$N$にあるとき、すべての空白文字(カテゴリーコード10の文字)を無視し、また行末文字を読んだときはこれを\parに置換します。空白文字と行末文字以外の任意の文字を読むと状態$M$に遷移します。
状態$M$:middle of line
状態$M$は最も一般的な状態で、カテゴリーコード1-4, 6-8, 11-13のいずれかの文字とコントロール・シンボル(コントロール・スペースを除く)が読まれたあとはこの状態に遷移しています。状態$M$にあるときに行末文字が現れると、空白トークンを1つ挿入して状態$N$へと遷移します。
状態$S$:skipping spaces
コントロール・ワードおよびコントロール・スペースのあとは必ずこの状態に遷移するほか、状態$M$において空白文字が現れたあとにもこの状態に遷移します。この状態にあるとき、入力プロセッサはすべての空白文字を無視します。また、行末文字を読んだときはそのトークンを破棄した上で状態$N$に遷移します。
各カテゴリーコードの詳細
0: 制御綴を開始(エスケープ文字)
通常はバックスラッシュ\がエスケープ文字に該当します。
制御綴はエスケープ文字によって開始されますが、そのエスケープ文字の文字コードが何であれ後続の文字列が一致するのであれば生成されるのは同じ制御綴です5。すなわち、以下の例で\csと|csはまったく同一の制御綴です。
\def\cs{cs}
\catcode`|=0
\ifx\cs|cs true\else false\fi %=>true
なお\stringや\writeによって制御綴を出力(文字列化)する場合は、TeXの内部値\escapecharで指定された文字が前置されます6。
\escapechar=`!
\string\cs %=>!cs
1, 2: グループの開始・終了
plain TeXやLaTeXでは{と}に設定されています。カテゴリーコード1, 2に属する文字が必要とされる多くのケースでは、\letや\futureletを用いて定義された暗黙的な文字が使用できます7$^,$8。plain TeXやLaTeXでは\bgroupと\egroupが暗黙的な文字として使えるようになっています。
\let\bgroup={
\let\egroup=}
カテゴリーコード1, 2に設定された文字がそれぞれ複数ある場合、カテゴリーコード1のどの文字で開始したグループであっても任意のカテゴリーコード2の文字で終了でき、また通常のグループについては明示的な文字と暗黙的な文字も一切区別されません。したがって、以下のコードは正当です。
\catcode`<=1
\catcode`>=2
{group 1}
{group 2>
<group 3\egroup
ところで、グループの開始・終了はプリミティブ\begingroup・\endgroupを用いても行うことができますが、これとカテゴリーコード1, 2の文字は互いに対応しません。つまり\begingroupで開始されたグループは必ず\endgroupで終わる必要があり、\endgroupで終了できるのは\begingroupでグループが開始されているときだけです。
この事実は、エラー箇所をみつけやすくするのに少しだけ役立ちます。例えば、以下のコードでは(作成者の意図としては)2行目の}が不整合(ミス)なわけですが、\bgroupと}でグループが形成できるため、エラーが発生するのは3行目の\egroupのところとなってしまいます。
\bgroup
}
\egroup %<-error
上の例で\bgroup,\egroupの代わりに\begingroupと\endgroupを使用すれば、実際の問題箇所でエラーが発生し、多少は修正すべき箇所を見つけやすくなるでしょう。
\begingroup
} %<-error
\endgroup
3: 数式・非数式の切り替え
カテゴリーコードが3の文字(通常は$)が単独で用いられた場合、インラインな数式モードに入ります。このとき複数種のカテゴリーコード3の文字や暗黙的な文字も区別なく使用できます。さらに、カテゴリーコード3の文字がマクロに被覆されていても機能します。
\def\mmode{$}
\mmode x\mmode %<-OK
また、カテゴリーコード3の文字が2つ連続するとディスプレイ数式の開始・終了を行うことができます9。このときも、複数種のカテゴリーコード3の文字や暗黙的な文字は区別なく使用できますが、2連続するべきカテゴリーコード3の文字の2つ目のみをマクロに含めたり、それぞれを別々のマクロに含めていたりするとディスプレイ数式に入ることはできません。
$\mmode x^2$\mmode %<-error
\mmode\mmode x^3\mmode\mmode %<-error
一方でディスプレイ数式の終了は、マクロ展開の結果カテゴリーコード3の文字が連続すれば別々のマクロに含まれていてたとしても問題ありません。
\def\MMODE{$$}
\MMODE x^4\mmode\mmode %<-OK
4: アライメントの区切り
カテゴリーコード4の文字(通常は&)はアライメントの区切りやアライメントプリアンブルにおける繰り返しの指定に用いられます。
文字の性質としては、アライメントの項目周りに中括弧が暗黙のうちにグループ化されたり、直後の空白が無視されたり10ということがありますが、これらの事項はここで詳述するよりもTeXのアライメントを説明する際に言及されるべきでしょう。
5: 行の終了(行末文字)
カテゴリーコード5の文字は行末文字として扱われるもので、通常は文字コード13の文字(改行)がこれに該当します。行末文字はそれが読まれたときのオートマトンの状態によって次のような挙動を示した後、オートマトンを状態$N$に遷移させます。
- 状態$N$の場合:
\parを挿入する - 状態$M$の場合:空白トークンを挿入する
- 状態$S$の場合:何も挿入しない
この改行文字が“実際の行”の途中に現れた場合(すなわち改行文字以外のカテゴリーコード5の文字が現れた場合)上記の動作が行われた後、“その行”の残りの部分は無視されます。したがって、以下のコードはfoo bazという入力と等価になります。
\catcode`!=5
foo!bar
baz
なお、TeXには\endlinecharという各入力行の行末に挿入される文字を指定するための内部値がありますが(規定では文字コード13が設定されています)、その値とカテゴリーコード5の文字は直接関係ありません。
6: パラメタ文字
plain TeXやLaTeXにおいては#がパラメタ文字として使用されています。パラメタ文字はマクロ定義の文脈(具体的には、パラメタテキストおよび置き換えテキスト)で登場した場合、かなり特殊な扱いを受けます。すなわち、TeX言語において制御綴以外は基本的に「1文字1トークン」という原則が成り立ちますが、マクロ定義の文脈におけるパラメタ文字についてはこれの例外事項にあたります。
- パラメタ文字に1-9の数字が後続する場合、1つのパラメタトークンを生成する11
- 置き換えテキスト中でパラメタ文字が連続すると、置き換え時には後ろの1つが残る
なお、マクロ定義の文脈以外でパラメタ文字が現れた場合は「1文字1トークン」の原則通りに字句解析されることになります。
7: 上付き文字
上付き文字としては通常^が使用され、多くのユーザが数式モードで上添字を付けるのに利用していることでしょう。
上付き文字のもう1つの利用法はサーカムフレックス・メソッドです。これは2連続する同一のカテゴリーコード7の文字に12
- 0-9, a-fの文字を用いて表現された高々2桁の16進数13
- 文字コードが128未満の1文字
のいずれかを後置することでこれらに対応する文字コードから64増減された文字コードに対応する文字を入力することができるというものです14。
なお、以前の記事でも述べたようにサーカムフレックス・メソッドで記述された表現は入力プロセッサが字句解析を行うよりも前に処理されるため、ほとんどあらゆる場面で使用可能です15。
8: 下付き文字
通常は_が下付き文字として使用されます。もちろん、数式内でしか使用できません。
ここで1つ一般的な注意をしておくと、TeX言語には特殊な状況でしか使用できないカテゴリーコードの文字があり(例えば、カテゴリーコード4の文字はアライメントの中、カテゴリーコード8の文字は数式の中でしか利用できません)、これらをそれぞれ“適切な場所”以外で使用すると大抵の場合はエラーになっていまいますが、これは字句解析の段階でエラーとなるわけではありません。字句解析の段階では、これらの文字も先ほど言及した「1文字1トークンの原則」にしたがってトークン化されます。
もちろん、それらの文字は最終的に展開あるいは実行されるときに“適切な場所”にないとエラーを引き起こします。しかし、逆に言えば実際に展開ないし実行されるまでに“適切な場所”に配置されるのであれば何ら問題は起こりません。したがって、以下の極めて邪悪なコード例はエラーも警告も吐くことなく、まったく正常に処理されます。
\def\Evil#1#2#3#4{% #1=&, #2=#, #3=^, #4=_
\halign{%
#2\hfil#1\hfil#2\cr
$x#3n$#1$a#4m$\cr
}}
\Evil&#^_
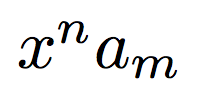
9: 無視される
このカテゴリーに属しているのは通常NUL(文字コード0)のみで、これは単純に無視されてオートマトンの状態もそのまま維持されます。
10: 空白文字
カテゴリーコード10の文字は、オートマトンの状態が $N$ または $S$ の場合には無視されます。状態が $M$ の場合は、その文字コードに関わらず、必ずカテゴリーコード10をもつ文字コード32のトークン(空白トークン)を挿入し16、状態 $S$ に遷移します。なお、この空白トークンとコントロール・スペース\␣は根本的にまったく異なるものなので混同しないよう注意してください。
\def\foo{ }
{\catcode`\!=10 \gdef\bar{!}}
\ifx\foo\bar true\else false\fi %=>true
ところで\let代入における=の後ろには余分な空白を1つおくことができ(もちろん、最終的にこれは無視されます)、また空白を実直にいくつか並べたとしても字句解析の段階で1つに縮約されてしまうので、暗黙な空白を作るには多少の工夫が必要です。例えば、以下のようにすることで暗黙な空白\bazを作ることができます。
\def\={\let\baz= }\=␣
11, 12: 英文字・記号
カテゴリーコード11, 12の文字がTeXのソースに記述された場合、大抵はそのまま紙面に印字されます。また、よく知られている通りエスケープ文字の直後で連続するカテゴリーコード11の文字は制御綴を形成します。
通常カテゴリーコード11, 12に属する文字が、制御綴の構成要素でなくてもそのまま印字されない別の用例としてTeX言語における「数値表現」や「キーワード」があります。これらの詳細についてはThe TeXbookなどに記載されたTeX言語の文法を参照して欲しいですが、カテゴリーコードに関わる部分について以下の規則が一般に成り立っています。
- 通常カテゴリーコード12に属することが期待される記号は、他のカテゴリーコードだと機能しない
- 単位やキーワードに用いる英文字は、カテゴリーコード11でなくても機能する17
ここで1. のケースに該当するのは主に数値に関連する記号で、数字0-9や符号+と-、$n$ 進数を表す",'の類、あるいは等号=などです。ただし、<number>の16進数表記に用いるA-Fはカテゴリーコード11, 12のいずれでも許容されます。
一方2. の規則が適用されるptを始めとする単位やbyなどのキーワードは、カテゴリーコード11でなくとも機能し、さらに大文字・小文字も区別されません。
ところで、\string, \number, \romannumeral, \jobname, \fontname, \meaning, \theといった「文字トークンの列を生成するプリミティブ」は、空白を除いてはすべて必ずカテゴリーコード12の文字トークンを生成します(空白だけはカテゴリーコード10)。TeXマクロのパターンマッチではカテゴリーコードについても考慮されるので、こうした命令で生成したトークン列に対してパターンマッチを行う際には注意が必要です。
13: アクティブ文字
アクティブ文字は単独で制御綴のように“命令”として用いることのできる文字です。plain TeXやLaTeXにおいては~がこれに該当します。
アクティブ文字は文字(文字コード)ごとに通常のマクロ定義と同様の方法でその動作を定義することができます。スコープの制御についても通常のマクロと同様です。ただし、アクティブ文字を利用する場合には定義時と使用時の両方で当該文字のカテゴリーコードを13に設定しておく必要があります。
なお、plain TeXやLaTeXでは\chardef\active=13のような定義がなされているため、13の代わりに\activeを使うことが可能です。
\catcode`+=\active \catcode`-=\active
\def+#1{!#1!} \def-{foo}
+- %=>!foo!
14: コメントの開始
カテゴリーコード14の文字(通常は%)はコメントを開始し、自身からその行の最後までを無視させます。TeX by Topicには「行末文字もTeXから見えなくなるので、状態 $M$ にあっても空白トークンは挿入されない」とあり、その主張自体は間違っていないのですが、実際には次の行の先頭から状態 $N$ で字句解析が再開するのでコメント部分に関してはオートマトンモデルの適用範囲外とみなすのが適当だと思います。
また、カテゴリーコード14の文字について暗黙的な文字を作ることはできないようです(少なくとも私は方法を知りません)。
15: 無効文字
カテゴリーコード15の文字は字句解析の時点でエラーを引き起こします。ただし、コントロール・シンボルとしては無効文字も使うことが可能です。
pTeX系列におけるカテゴリーコード
日本語を扱うことのできるTeX処理系では、いわゆる2バイト文字(全角文字)などASCIIの範囲に収まらない文字についても考慮する必要があります。本節ではpTeX系列におけるカテゴリーコードについて簡単な解説を試みます。
なお、LuaTeX-jaのカテゴリーコードについては公式ドキュメントの第5章に詳しい解説があるので、ここでは扱いません。
2バイト文字のカテゴリーコード:kcatcode
pTeX系列のTeX処理系(特に非upTeX)においては、原則として2バイト文字については\catcodeを使用しません18。代わりに、2バイト文字に対しては\kcatcodeプリミティブを用います。\kcatcodeの基本的な使い方は\catcodeとまったく同様です。以降本節では、\catcode命令によって取得・変更するカテゴリーコードをcatcode、\kcatcode命令によって取得・変更するカテゴリーコードをkcatcodeと区別して表記することにします。
kcatcodeの値としては、pTeXの場合は16-18、upTeXの場合は15-19をとることができ、その基本的な意味や役割は以下の表の通りです19。
| kcatcode | 意味(意図) | コントロール・ワードでの使用 |
|---|---|---|
| 15 | CJK以外 | catcodeに依存 |
| 16 | 漢字 | 可 |
| 17 | かな | 可 |
| 18 | その他 | 不可 |
| 19 | ハングル | 可 |
なお、kcatcodeの非漢字文字のデフォルト値はかなり複雑で、また環境によっても異なるため、これを網羅的に調査するためのスクリプトkct.shが北川氏によって開発されています。
kcatcodeの変更
\kcatcodeを用いると、\catcodeによるcatcodeの変更と同様の書式でkcatcodeを変更することができますが、catcodeと異なりkcatcodeの場合は文字コードごとに設定されるわけではなく、指定した文字コードを含むあるグループ全体のkcatcodeが変更されます。ここで、kcatcodeの変更単位(本稿では以降「kcatcodeグループ」と呼ぶことにします)は処理系に依存します。
まずpTeXの場合ですが、pTeXの中でも旧来のアスキー版かTeX Live収録のものかによって次のように異なります。
- アスキー版pTeX:内部コードの上位バイトごと
- TeX Live版pTeX:JISコードの上位バイト(区)ごと
この事実から、アスキー版のpTeXにおけるkcatcodeグループは内部コードShift-JISかEUCかなどに依存して変化してしまうことが予想されます20。TeX Live版pTeXではkcatcodeグループをJISコード本位に固定することによって、結果的に区点コード単位の変更を可能にしているようです。
一方、upTeX処理系ではkcatcodeの変更をUnicodeのブロックごとに行うことができます。特にkcatcodeを15に設定すると欧文の8-bit文字(catcodeによる制御が有効)として扱われるため、(非pTeX系エンジンで使用することを意図して開発された)他言語用の成果物の機能を利用できるようになります。
おわりに:参考文献など
当初はそれほど詳しいことを書く予定ではなかったのですが、ゼミ中に噴出した疑問点を整理し、行った数々の実験の結果も盛り込んだところこのように長い記事となってしまいました。結果的に、TeX by Topic以外の文献も多数参照することとなりました。ここでは、それらの参考文献を紹介文を挟みつつ列挙しておこうと思います。
- Knuth, D. (1982). TeX82. http://mirror.ctan.org/systems/knuth/dist/tex/tex.web.
- Knuth, D. (1986). The TeXbook. Reading, Mass. u.a: Addison-Welsey.
まずはTeXの作者Knuthによる文献です。配列順はともかくとして、The TeXbookにはTeX言語に関して必要な事項はだいたい記述されています。1つ目のtex.webは正真正銘「TeXのソースコード」ですが、よく知られているようにKnuthの提唱する文芸的プログラミングの実践例となっており、実際拾い読みでも意外と読めてしまうものでした。
- Bechtolsheim, S. (1993). TeX in Practice: Volume III. New York: Springer-Verlag.
- Salomon, D. (1995). The Advanced TeXbook. New York, NY: Springer New York.
上記2冊はいずれもTeX言語に関する、かなり発展的なSpringer書籍です。TeX in Practice: Volume IIIの18.1.8節にiniTeXにおけるカテゴリーコードの設定について解説がありますが、カテゴリーコード5と10の説明が逆になっているので注意が必要です。
- ページ・エンタープライゼズ㈱. (2002). LaTeX2e【マクロ&クラス】プログラミング基礎解説
TeX (on LaTeX)についてかなり踏み込んだ解説がなされた貴重な和書で、しばしば「黄色い本」と呼ばれています。余談ですが、筆者はこの本の続編にあたる『LaTeX2e【マクロ&クラス】プログラミング実践解説』(通称:緑の本)を最近入手しました。
- アスキー㈱. (2011). 漢字コードについて - pTeX home page
- 北川典弘. (2016). TeX Live 2016におけるpTeX系列のプリミティブ
- 田中琢爾. (2017). upTeX, upLaTeX — 内部unicode版pTeX, pLaTeXの実装 (Ver1.22)
- upTeX, upLaTeX - TeX Wiki
前半3文献は、いずれもpTeX系エンジン開発者ご自身によるドキュメントです。pTeX系列におけるカテゴリーコードの扱いについて言及のある資料はかなり希少です。
- TeX芸人の知らない
#の挙動 | hak7a3が書き残す何か - 本当に怖いTeXの字句解析の話 | マクロツイーター
- 本当に怖いTeXの字句解析の話(負け惜しみ編) | マクロツイーター
- 本当に本当に本当に怖いTeXの字句解析の話 | マクロツイーター
最後に列挙したのは、いずれもブログ記事です。hak7a3氏の記事ではTeX言語における#の挙動について、これ以上にないほど詳しく解説されています。最後の3項目は某ZR氏によるカテゴリーコードに関する連載記事です。

主な更新履歴
- 2019-09-22: いくつかのリンク切れを解消しました
-
ただし
\advance等による演算を行うことはできません。 ↩︎ -
正確にはTeXの内部コードですが、0以上127以下の範囲についてはASCIIコードと一致しています。 ↩︎
-
逆に、同じトークンでも制御綴の場合はカテゴリーコードの情報は含みません。 ↩︎
-
e-拡張に含まれるプリミティブ
\scantokensを用いると例外的に一度TeXに認識された文字のカテゴリーコードを変更することが可能です(参考)。 ↩︎ -
これはトークンとしての制御綴にはもはやエスケープ文字の情報が含まれていないことを意味します。 ↩︎
-
\escapecharの値が0以上255以下の範囲にない場合は何も前置されません。 ↩︎ -
状況によって明示的な文字しか使えない場合、暗黙的な文字しか使えない場合、両方使用可能な場合があります。なお、The TeXbookやTeX by Topicで用いられているBNF記法によるTeX言語の文法記述(の右辺)においては、
{のように明示的に文字が書かれている場合にはその文字と同じカテゴリーコードをもつ文字と同義の暗黙的な文字が許容されるのに対して、<left brace>のように山括弧で囲われたメタ変数で表されている場合には明示的な文字である必要があり、これは少しばかり直感に反するので注意が必要です。 ↩︎ -
一般に暗黙的な文字が利用できるのは、基本的に文字コードとは無関係に特定のカテゴリーコードに属する単一の文字が求められる状況だけです。したがって、
ptなどの単位やplusなどのキーワード、あるいは種々の数値表現の中で用いられている文字の一部を暗黙的な文字で代用することはできません。これは暗黙的な文字はマクロではないため「展開」されることがないことに起因するようです。 ↩︎ -
ただし
\$a$$b$のような入力の場合はインライン数式が2つと解釈されます。TeXの処理系はトークン列を前から順々に読みつつ展開・実行していくため、この挙動は当然といえば当然です。 ↩︎ -
これはコントロール・ワードの後の空白が無視されるメカニズムとは根本的に異なり、字句解析の時点で空白が落ちるわけではありません。 ↩︎
-
パラメタトークンを作るために後置する数字は、カテゴリーコード12でなければなりません。 ↩︎
-
置き換えテキスト内でのパラメタ文字のエスケープは連続するカテゴリーコード6の文字であれば何でも機能しますが(すなわち
#,@がカテゴリーコード6に属するとき#@は許容される)、サーカムフレックス・メソッドの場合はカテゴリーコードだけでなく文字コードも一致している必要があります。 ↩︎ -
TeX言語の一般的な数値表現
<number>における16進数表記("から始まる)では大文字A-Fを使用するのに対して、ここでは小文字a-fを使用するので注意が必要です。ちなみに、サーカムフレックス・メソッドで16進数表現が利用できるのはTeXのversion 3以降です。 ↩︎ -
サーカムフレックス・メソッドにおける16進数およびASCII文字1文字として使用する文字のカテゴリーコードは何でも構いません。 ↩︎
-
当然ですが「展開や実行の結果
^^{char}の形が完成する」ようなものはサーカムフレックス・メソッドとして処理されません。また、サーカムフレックス・メソッドによる表現を、さらにサーカムフレックス・メソッドでエンコードすることもできません。 ↩︎ -
カテゴリーコードが10で、文字コードが32でない文字トークンは
\lowercaseトリックを用いることにより生成できます(参考)。 ↩︎ -
字句解析の時点で期待する文字コードをもつ文字トークンを生成しなくなってしまうようなカテゴリーコード(0, 5, 9, 10, 14, 15)の文字やアクティブ文字を含む場合はこの限りではありません。 ↩︎
-
従来のpTeX系列処理系では
\catcodeの引数に2バイトコードを与えると、その上位バイトの値に従ってそのカテゴリーコードを取得したり変更したりすることができましたが(ただし引数によっては落ちる)、TeX Live 2017収録のpTeX系列処理系では禁止される見込みです。 ↩︎ -
kcatcodeの値ごとの差異はコントロール・ワードで使用できるか否か以外にも、文字ウィドウ処理や直後の改行が無視されるかどうかなどということがあります。それらについてはLuaTeX-jaドキュメントの表5に詳しく掲載されています。 ↩︎
-
アスキーによれば、従来のアスキー版pTeXではそもそも2バイト文字のkcatcodeは変更できなかったはずです。また、田中氏によるとpTeXにおける2バイト文字トークンはkcatcodeの情報をもっておらず、字句解析時と展開・実行時の双方で必要に応じてkcatcode表を参照して文字コードに対応するkcatcodeを取得する実装になっているようです。このため、特定グループのkcatcodeの値を動的に変更すると(見かけ上)字句解析の終了している「文字トークン」のカテゴリーコードをあとから変更できてしまうと推測されます。 ↩︎